
_We write about the tools in Anyshift's ecosystem: the CLIs and platforms that Annie integrates with. This one is about acli, Atlassian's command-line interface for Jira. It's the third in a series with Annie meets pup and Annie meets gcx._
The Problem
In this demo, a developer opens pull request #1923. It modifies validate_session() in shared/auth/session.py, a shared authentication module. Three services in production import it: checkout-service, notification-worker, and inventory-sync. Their teams (payments, notifications, catalog) should know now, not a sprint later when something breaks in staging.
PR #1923 (shared/auth/session.py)
│
├─→ checkout-service → payments
├─→ notification-worker → notifications
└─→ inventory-sync → catalogThe information existed while the pull request was still open: which services consume the change, which teams own them, who reviewed the last similar change. Jira is the right place for that work to land. The hard part is deciding where to file it before the work exists.
That decision comes from production, not from the Jira issue alone.
Why this belongs in Jira
Jira is where teams coordinate the follow-up work: who owns it, which team board it belongs on, what evidence is attached, and whether it is linked to a parent issue or an existing ticket.
Annie can decide what follow-up work is needed before the ticket exists because it reads Anyshift's production context: running services, dependency paths, deploy history, PR provenance, and ownership.
For Atlassian readers, this fits the direction of Teamwork Graph: Jira and Rovo keep work context connected; Annie brings in the production impact that tells that work where to land.
From PR Impact To Jira
annie do takes one pull request and prepares the Jira work: one parent issue (the grouping ticket) plus one advisory ticket (the heads-up) for each affected team. If the graph resolves a reviewer, the advisory is assigned before acli writes to Jira.
For "PR #1923" the routing is:
checkout-serviceimports the changed function, so Payments (PAY) gets an advisory.notification-workerimports it too, so Notifications (NOTIF) gets one.inventory-syncdepends on it throughlib-common@2.4.1, so Catalog (CAT) gets one.- deprecated or sandbox-only services are skipped.
- an existing advisory from a nearby PR is linked, not duplicated.
That context comes from code paths, deploys, ownership history, and the PR itself.
That is the handoff: Annie prepares and saves the plan; acli executes it in Jira after approval.

annie do writes a runbook (the YAML plan reviewed before execution). It includes the impact evidence and the exact acli commands.
acli then uses Jira's own authentication to create, bulk-create, and link the work items.
The generated files
annie do output: YAML with the PR impact.

acli step: Annie converts the plan into the JSON that create-bulk expects.

After approval, acli creates the parent issue, creates the child advisories, then links each child back to the parent. The last step reads the parent issue key, loops over each child ticket key, and asks acli to create one Jira relationship link, Relates, per child:

Before approval, the affected teams' Jira boards have no tickets for the PR #1923 yet. Annie has found the impact; Jira has not received the work yet.
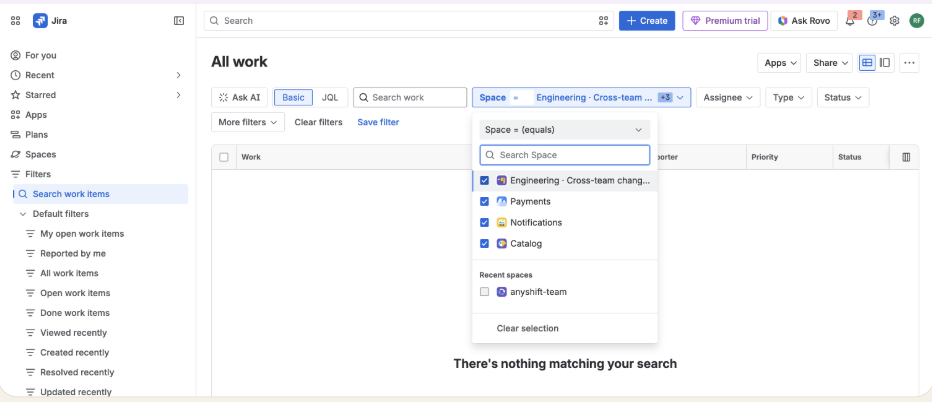
_Before: Annie has found the impacted services. Jira has no advisory work yet._
After annie do finishes, a parent issue appears in ENG with three tickets linked under it. Each ticket lands on the right team's board. PAY has the routed reviewer; the other teams use the project default.
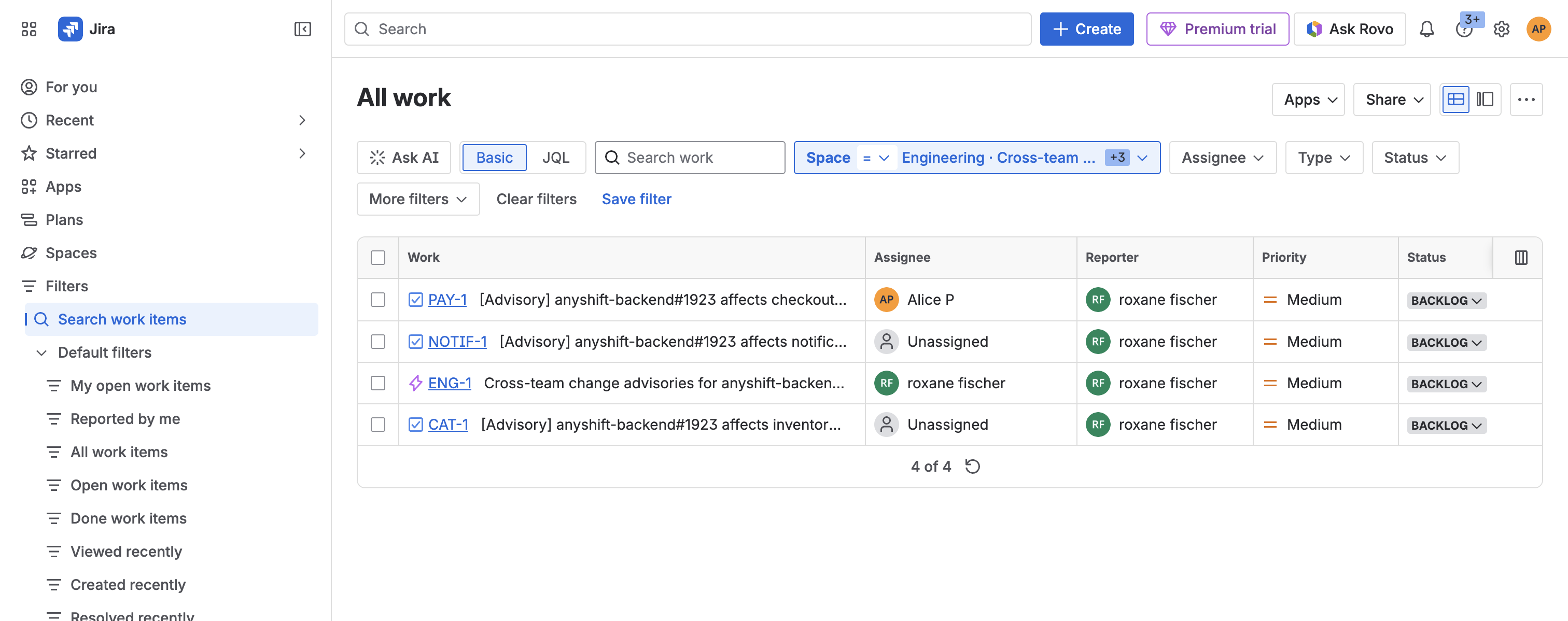
_After: one parent issue, three tickets, on the right boards. PAY has its routed assignee; the others fall back to project default._
Where it is going
acli is the third vendor CLI Annie hands off to. The pattern stays the same: read the production context, render a runbook, hand it to the tool that owns the writes.
For Atlassian, the bigger path is a Teamwork Graph connector that makes Anyshift's infrastructure memory available wherever Jira agents need production impact. The acli demo is the first concrete step: a native Jira write, with review before execution, backed by production evidence.
The verbs we'd run next on the same shape:
- Continuous ticket sync as production context changes. A service moves to a new team and the open ticket gets reassigned. A code path gets renamed and the affected tickets get an updated link. A blast radius grows and the priority moves with it.
- Dedup against open work. Before filing a new ticket, annie do searches Jira for any already referencing the same module. If one exists, evidence is appended as a comment instead of a fresh duplicate landing on the team's board.
- Stale-ticket cleanup. The graph knows when a code path is deprecated or a service is decommissioned. annie do scans its open tickets and closes the ones whose underlying issue has resolved, with a comment explaining why.
